Our research centers on UNIfied-MOdal learning (UNIMO), integrating diverse data modalities, such as text, images and other modalities, for advanced multimodal understanding and generation.
News:
- [2024.01.25] UNIMO-G released on arxiv.
- [2022.02.24] UNIMO-2 accepted by Findings of ACL 2022, long paper.
- [2021.05.06] UNIMO accepted by Main Conference of ACL 2021, long paper.
UNIMO-G: Unified Image Generation through Multimodal Conditional Diffusion
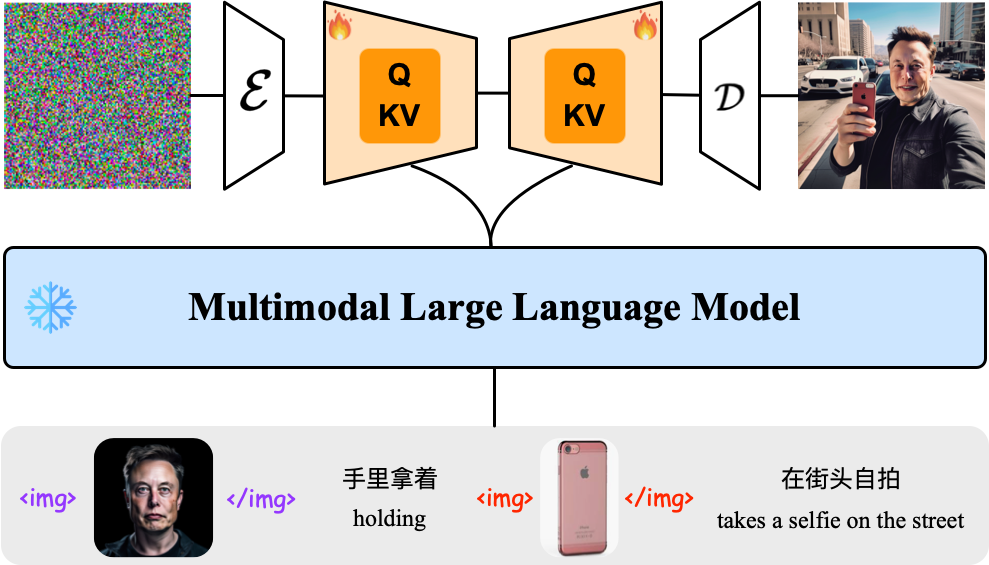
Existing text-to-image diffusion models primarily generate images from text prompts. However, the inherent conciseness of textual descriptions poses challenges in faithfully synthesizing images with intricate details, such as specific entities or scenes. This paper presents UNIMO-G, a simple multimodal conditional diffusion framework that operates on multimodal prompts with interleaved textual and visual inputs, which demonstrates a unified ability for both text-driven and subject-driven image generation. UNIMO-G comprises two core components: a Multimodal Large Language Model (MLLM) for encoding multimodal prompts, and a conditional denoising diffusion network for generating images based on the encoded multimodal input. We leverage a two-stage training strategy to effectively train the framework: firstly pre-training on large-scale text-image pairs to develop conditional image generation capabilities, and then instruction tuning with multimodal prompts to achieve unified image generation proficiency. A well-designed data processing pipeline involving language grounding and image segmentation is employed to construct multi-modal prompts. UNIMO-G excels in both text-to-image generation and zero-shot subject-driven synthesis, and is notably effective in generating high-fidelity images from complex multimodal prompts involving multiple image entities.
The releated resources will be released at: [UNIMO-G]
UNIMO-2: End-to-End Unified Vision-Language Grounded Learning
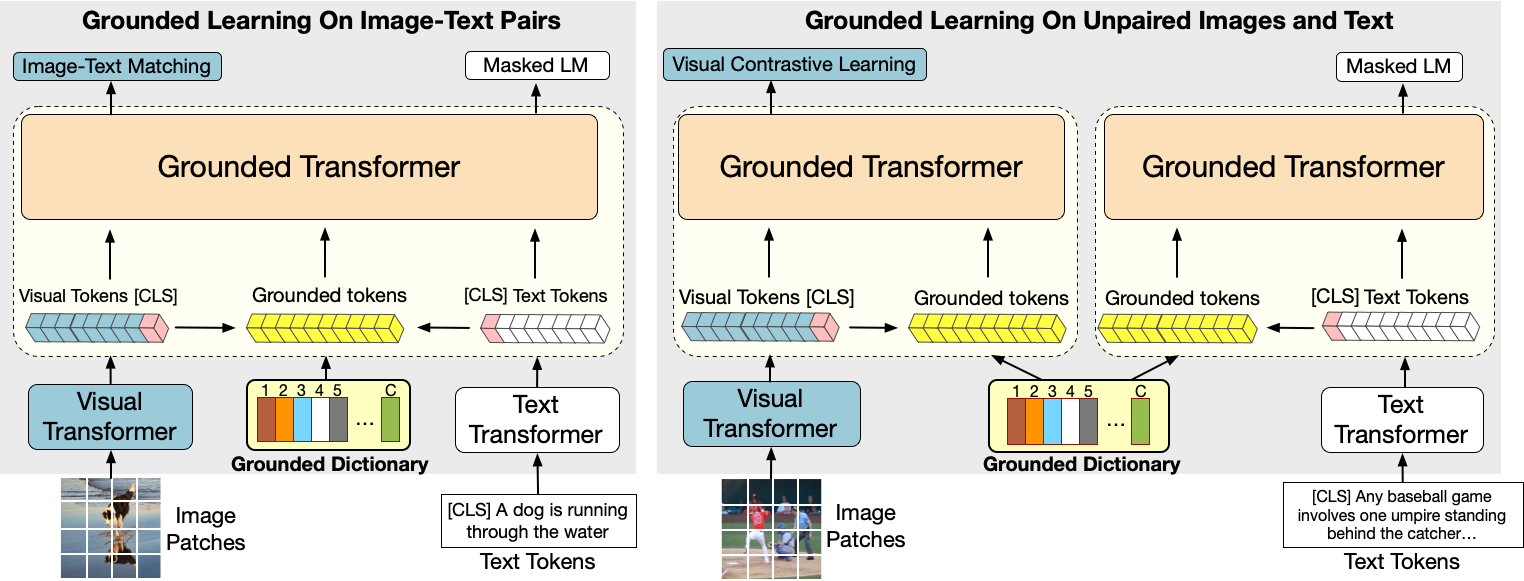
Vision-Language Pre-training (VLP) has achieved impressive performance on various cross-modal downstream tasks. However, most existing methods can only learn from aligned image-caption data and rely heavily on expensive regional features, which greatly limits their scalability and performance. In this paper, we propose an end-to-end unified modal pre-training framework, namely UNIMO-2, for joint learning on both aligned image-caption data and unaligned image-only and text-only corpus. We build a unified Transformer model to jointly learn visual representations, textual representations and semantic alignment between images and texts. In particular, we propose to conduct grounded learning on both images and texts via a sharing grounded space, which helps bridge unaligned images and texts, and align the visual and textual semantic spaces on different types of corpora. The experiments show that our grounded learning method can improve textual and visual semantic alignment for improving performance on various cross-modal tasks. Moreover, benefiting from effective joint modeling of different types of corpora, our model also achieves impressive performance on single-modal visual and textual tasks.
The code and pre-trained models have been released at: [UNIMO-2]
UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
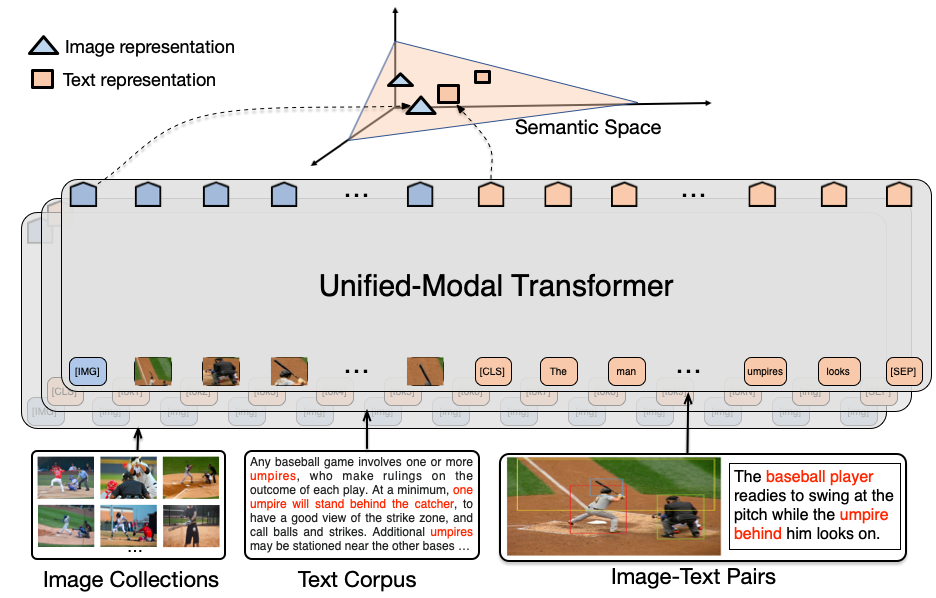
Existed pre-training methods either focus on single-modal tasks or multi-modal tasks, and cannot effectively adapt to each other. They can only utilize single-modal data (i.e., text or image) or limited multi-modal data (i.e., image-text pairs). In this work, we propose a UNIfied-MOdal pre-training architecture, namely UNIMO, which can effectively adapt to both single-modal and multi-modal understanding and generation tasks. Large scale of free text corpus and image collections are utilized to improve the capability of visual and textual understanding, and crossmodal contrastive learning (CMCL) is leveraged to align the textual and visual information into a unified semantic space, over a corpus of image-text pairs augmented with related images and texts. With the help of rich non-paired single-modal data, our model is able to learn more generalizable representations, by allowing textual knowledge and visual knowledge to enhance each other in the unified semantic space. The experimental results show that UNIMO greatly improves the performance of several singlemodal and multi-modal downstream tasks.
Our code and pre-trained models have been released at: [UNIMO]
Publications:
- [Arxiv 2023] Wei Li*, Xue Xu*, Jiachen Liu, Xinyan Xiao. UNIMO-G: Unified Image Generation through Multimodal Conditional Diffusion. [PDF] [code] (* indicates equal contribution)
- [ACL 2022] Wei Li, Can Gao, Guochenng Niu, Xinyan Xiao, Hao Liu, Jiachen Liu, Hua Wu and Haifeng Wang. UNIMO-2: End-to-End Unified Vision-Language Grounded Learning. Findings of ACL 2022, long paper [PDF] [code]
- [ACL 2021] Wei Li*, Can Gao*, Guochenng Niu*, Xinyan Xiao*, Hao Liu, Jiachen Liu, Hua Wu and Haifeng Wang. UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning. ACL 2021 long paper, Main Conference. (* indicates equal contribution) [PDF] [code]